CogniFlow Architectural Deep Dive
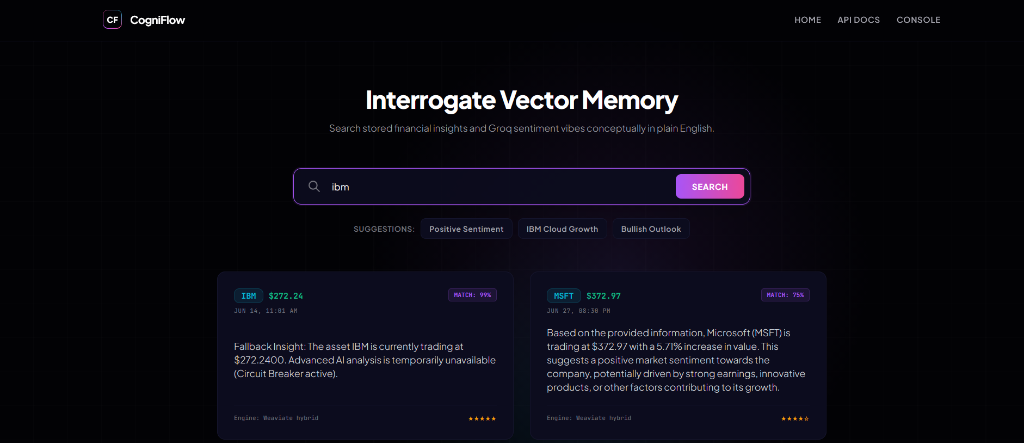
Selected Weaviate as the core vector database to avoid proprietary SaaS vendor lock-in and ensure self-hosted deployment. This provides out-of-the-box support for high-speed hybrid search—merging BM25 keyword matching with HNSW semantic vector retrieval—which is crucial for precise stock earnings insight analysis.
Show technical deep-dive
Ingestion Pipeline Automation
A serverless workflow scheduled daily queries stock filings via APIs, processes the textual content with Gemini LLM models for key extraction, computes vector embeddings, and indexes them directly in Weaviate.
Defensive Embedding Fallbacks
To mitigate network timeouts and vector database connection latency, local tokenization logic intercepts exceptions and serves pre-cached mock semantic data so dashboard renders are never blocked.